Hierarchical Reinforcement Learning as Creative Problem Solving
A theoretical and experimental project exploring the relationship between hierarchical reinforcement learning, the psychology of insight, and computational creativity.
This was the central research thread of my PhD, supervised by Tony Belpaeme at Plymouth University. It sits at the intersection of reinforcement learning, cognitive psychology, and computational creativity. The standard definition of creativity emphasizes the product: a novel, valuable idea or behavior. A more useful question, at least for anyone trying to build creative machines, is what cognitive process produces it. This project takes that question seriously, focusing on a specific and well-studied phenomenon: insight.
Insight is the sudden resolution of a problem that had previously resisted solution, the “Aha!” moment familiar to mathematicians and scientists, and inferred from the behavior of animals in classic psychology experiments. It follows a characteristic sequence: search, impasse, restructuring, sudden solution. The interesting step is restructuring: a change not in the approach to solving the problem, but in the representation of the problem itself. The classic example is Köhler’s chimpanzees: when a banana was placed out of reach, they eventually realized that a box in the enclosure could serve as a stepping stone. The solution required reframing the box, a change in how the problem space was represented, not just a continuation of prior search.
Reinforcement learning, briefly
Reinforcement learning (RL) is a framework for training agents to make sequential decisions. An agent observes a state, takes an action, receives a reward, and updates its behavior accordingly. The objective is to find a policy (a mapping from states to actions) that maximizes reward over time.
Hierarchical reinforcement learning (HRL) extends this by introducing a hierarchy of policies. Rather than selecting individual actions at each step, the agent selects “options,” temporally extended sub-behaviors that run until a termination condition is met. A high-level policy selects which option to pursue; each option has its own internal policy for action selection. When an option fails to make progress, the high-level policy can switch to a different option, starting fresh with a different state abstraction and set of available actions.
The argument
In my 2016 paper (with Belpaeme, Cangelosi, and Hemion), I argued that this switching mechanism is structurally analogous to the restructuring step in insight. When an HRL agent switches options, several things change at once: which features of the environment are relevant (state abstraction), the heuristics guiding search (the option’s value function), and the constraints on available actions. These map directly onto the changes that psychological research has identified as constituting restructuring in humans and animals. Finally, when a switch succeeds, the new representation can immediately reveal a path to reward that the previous one had missed entirely. The resulting spike in the agent’s value estimate, a large positive prediction error driven not by any external event but by the restructuring itself, is the computational correlate of the “Aha!” moment.
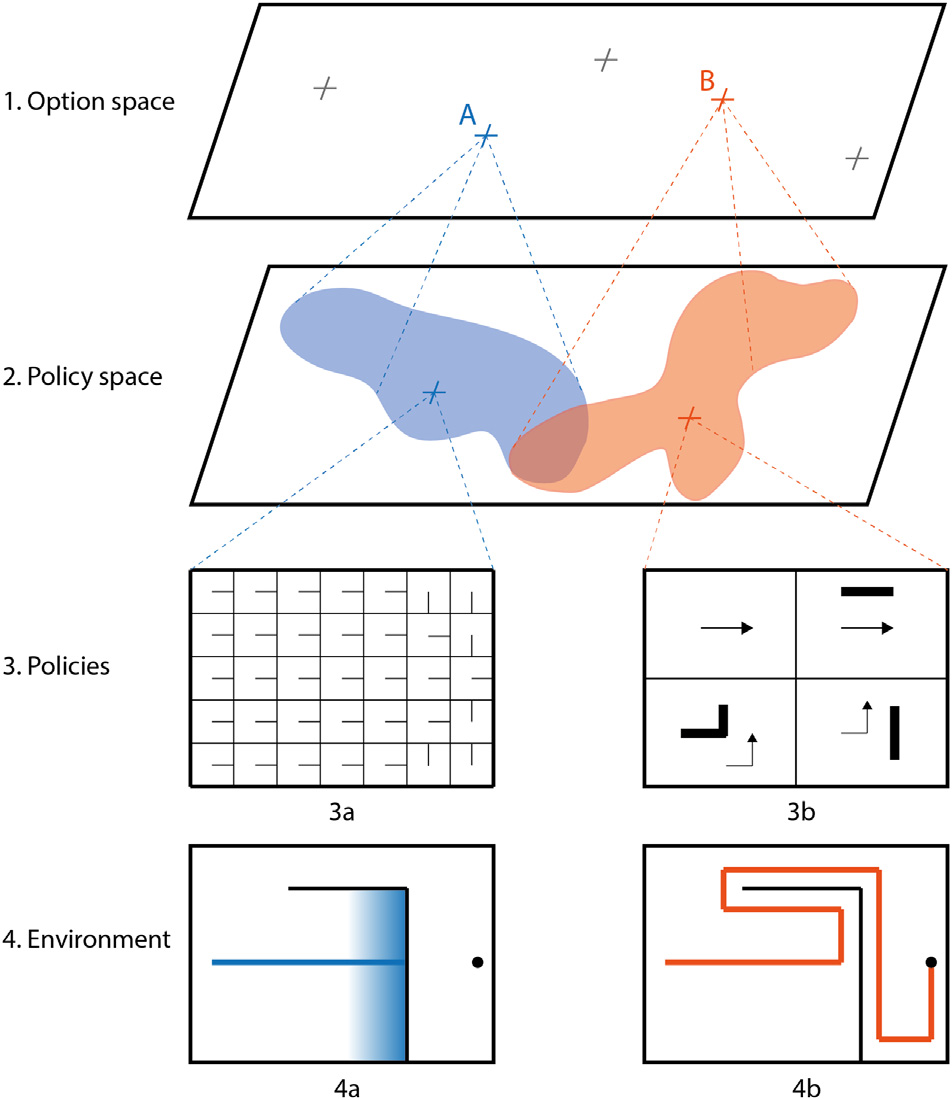
Fig. 1. A navigation task illustrating the analogy between insight and HRL. At the top level (option space), the agent selects between two options, A and B. Each option induces a different policy (rows 3a and 3b): option A represents the environment in grid coordinates and repeatedly bumps into walls; option B uses a wall-following representation and immediately succeeds. Switching options mid-task corresponds to the restructuring step in insight.
The parallel is made precise using the Creative Systems Framework (CSF), a formal account of creativity as search at two levels: object-level search (solving a problem within a given representation) and meta-level search (changing the representation when object-level search fails). In these terms, exploitation of the current option is object-level search; option-switching is meta-level search. The paper establishes a point-for-point correspondence between the properties of insight as described by psychologists and the properties of HRL algorithms.
The simulation
A companion paper (with Belpaeme, 2019) tests whether a deep RL agent actually produces insight-like behavior in practice. The testbed is a simulation of a classic experiment by Epstein et al. (1984): pigeons, pre-trained on two sub-behaviors (pushing a box toward a target, and jumping to peck at suspended food) spontaneously combined them to solve a novel test problem. Psychologists read this as insight; the pigeons had to generalize one trained behavior to a new context and combine it with another.

Fig. 2. Successive frames of a simulated pigeon solving the push-to-spot shaping task, one of the two sub-behaviors trained prior to the test. The agent first pushes the box in the wrong direction, then corrects course (note also the stochasticity of all action outcomes).
Simulated agents trained under analogous conditions reproduced several qualitative characteristics of insight: a period of low performance (impasse), followed by a sudden increase in success rate accompanied by a spike in positive prediction errors, the agent’s internal signal that something unexpectedly good has happened. Agents with moderate prior training performed better than those with none. Agents with extensive training sometimes did worse, consistent with the psychological finding that over-training on a particular approach can impede restructuring.
The simulated pigeons required substantially more trial and error than the real ones. The paper is explicit that this is a partial model: it captures the behavioral shape of insight, not its neural substrate.
Further formalization
Lahikainen, Ady, and Guckelsberger (2024) extend the formal analysis from hierarchical MDPs to Markov Decision Processes more generally. MDPs are the standard mathematical formalism for sequential decision problems; the 2016 paper used the options framework, a hierarchical specialization, as its unit of analysis. The generalization widens the scope considerably. They identify eleven possible mappings between MDP components and Boden’s creativity theory (formalized via the CSF) and examine three in detail, developing quality criteria for assessing each. Their work corrects several limitations of the original: the 2016 mapping was motivated by robot control specifically, and did not integrate uninspiration (failure modes for creativity) or aberration (boundary violations that can trigger creative shifts) into the analysis.
Artificial insight in the time of LLMs
These formal frameworks were developed when building a creative machine was an open research goal. Since then, AI systems have changed substantially enough to revisit the question empirically rather than theoretically. The framing above (options as discrete, time-bounded sub-policies that switch when they fail) was a reasonable formalization in 2016, when the question of whether any machine could exhibit creativity was largely theoretical. It is worth revisiting in light of what has since been built.
Large language models with transformer architectures approach the problem from a different direction. Rather than representing behaviors as discrete, bounded options with explicit termination conditions, transformers capture the statistical structure of sequential behavior (here, language production) as dense, overlapping, multivariate patterns distributed across many dimensions. A transformer does not commit to a discrete sub-policy; instead, it encodes the regularities of behavioral sequences in a form that is simultaneously more general and more flexible than the options framework. This scales far better: the same architecture, trained on sufficient data, learns to generate coherent long-horizon outputs across an enormous variety of domains without requiring any hand-specification of sub-policies, termination conditions, or option structures. This is, in a meaningful sense, a better solution to the representational problem the options framework was trying to address.
Modern reasoning-focused LLMs do exhibit behavior that superficially resembles the impasse-and-restructuring sequence: a model working through a problem will sometimes produce something like “Wait, that can’t be right” before pivoting to a different approach. This has been documented empirically in extended chain-of-thought settings.
Is anything still missing?
The similarity breaks down at the next step. In humans, insight transfers rapidly to lasting change: once the restructured representation is found, it propagates into future behavior. LLMs have no such mechanism. Lacking continual learning, they can produce the same erroneous reasoning in the same context across independent sessions, with no accumulation of understanding from prior errors.
A related failure mode is what might be called tunnel vision. LLMs can be steered toward different modes of response through prompting, but they maintain a strong prior toward the most statistically salient patterns in their training distribution. Even after explicitly establishing that an initial approach is wrong, they tend to drift back toward it, particularly over long contexts. The option-switching mechanism in HRL is triggered by a specific internal signal (negative prediction error); in LLMs, the analog is externally imposed through the context window, and it degrades.
There is also no analog to the affective component of insight. The positive prediction error that marks successful restructuring in an RL agent is an intrinsic signal of doing well, grounded in the agent’s own running estimate of expected reward. A model trained by supervision and then frozen has no such signal: no estimate of value, no internal indication that a pivot has paid off, no sense that one answer is better than another except insofar as the training distribution preferred it.
Finally, and most fundamentally, LLMs are trained mostly by supervision and their weights are subsequently frozen. There is no exploratory mechanism capable of generating improvement on genuinely novel problems. An RL agent interacts with an environment and receives feedback on actions it has not taken before; gradual improvement on new problem classes is what the temporal difference mechanism is for. An LLM can only pattern-match to what exists in its training distribution. For problems outside that distribution, there is no path to competence through experience.
Whether these gaps matter for creativity depends on what creativity requires. When this work was written, AI creativity was a legitimate open research objective. By 2026, creative behavior in AI systems is sufficiently commonplace to evaluate directly, which gives these older theoretical frameworks a new kind of relevance: not as blueprints for building creative machines, but as analytical tools for understanding what current systems are and are not actually doing.
This work formed the bulk of my PhD, supervised by Tony Belpaeme at Plymouth University, and produced a number of conference and workshop publications alongside the two primary papers listed below. A three-month research visit to the Reinforcement Learning and Artificial Intelligence (RLAI) lab at the University of Alberta in 2016 was particularly generative: conversations with Rich Sutton (whose foundational work on temporal difference learning and the options framework much of this builds on) and Nadia Ady (a co-author of the 2024 follow-up) sharpened the formal claims considerably.
Publications
- T.R. Colin, T. Belpaeme, A. Cangelosi, N. Hemion · Hierarchical reinforcement learning as creative problem solving · Robotics and Autonomous Systems, 2016
- T.R. Colin, T. Belpaeme · Reinforcement learning and insight in the artificial pigeon · CogSci, 2019
- J. Lahikainen, N.M. Ady, C. Guckelsberger · Creativity and Markov Decision Processes · arXiv, 2024