Atari ACC Model
A computational model of the anterior cingulate cortex, developed during a postdoc in Clay Holroyd's lab at Ghent University. ACC modules trained on top of a deep RL agent playing Q-bert learn to track and represent the agent's internal state — demonstrating that a separate observer module can recover structured, abstract representations of a complex neural system in action.
This project was carried out during my postdoc in Clay Holroyd’s lab at Ghent University. See my CV for context on that period.
The anterior cingulate cortex (ACC) is a brain region associated with cognitive control: the capacity to override routine, habitual behavior when it stops working. Holroyd’s controllosphere theory proposes that the ACC acts primarily as an observer: it monitors the state of the brain’s behavioral systems and tracks whether control efforts are having their intended effect. Per that hypothesis, actual control is handled elsewhere (primarily by the dorsolateral prefrontal cortex); the ACC’s job is to watch and know.
This project operationalizes that idea. A deep reinforcement learning agent is trained to play the Atari game Q-bert, standing in for the brain’s habitual learning system. A family of separate ACC modules are then trained to track the agent’s internal state (its activations, value estimates, and behavioral trajectory) without influencing its behavior. The task and the network are both genuinely complex, so it was not a given that a separate module could successfully learn to represent the internal state of another neural network from the outside. Establishing that it can is the core proof of concept, and it opens the door to follow-up work: using those representations to exert cognitive control, and validating the model against human neural representations via fMRI.
Why Q-bert
Q-bert has useful properties for this kind of work. Episodes are long and internally structured, with clear subgoals: complete the pyramid level by level, evade enemies, collect bonuses. Different levels look superficially different (colors change, new enemy types appear, and tiles may need to be jumped on twice in later levels), but the core goal (get all tiles to a uniform color by jumping on them) and the general shape of the required strategies persist across levels. This makes it a good test of whether learned representations track something abstract and generalizable, or just surface features. Game state (level, enemy positions, lives, score) can also be read directly from pixel values with simple image processing, enabling rich behavioral logging without any special instrumentation.




Different Q-bert levels. Colors and enemy configurations change across levels (later levels introduce new enemy types and require jumping on each tile twice), but the goal structure and the broad shape of successful policies remain recognizable throughout.
Base model
The base model is a standard deep RL agent using the A2C (Advantage Actor-Critic) algorithm. Four stacked grayscale frames go into three convolutional layers, which feed a two-headed network: an actor that selects actions and a critic that estimates state value. The implementation is custom; existing open-source baselines were difficult to extend for recurrent architectures, so the whole thing was built from scratch. It achieves approximately 20,000–30,000 points per game, consistent with expected A2C performance on this task.
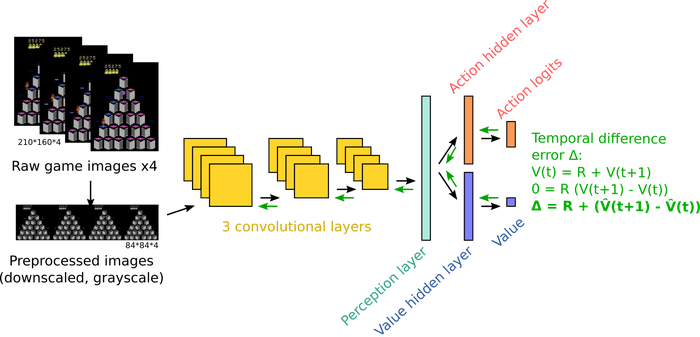
The base model architecture. Standard deep RL (A2C): convolutional perception layers feeding an actor and a critic.
ACC modules
Four observer modules were built, each representing a different hypothesis about what the ACC represents and how. All four are purely observational: they track the base model’s internal state without influencing its behavior, consistent with the controllosphere view of ACC function.
Autoencoder: learns a compressed representation of the base model’s activations at each time step. Treats states independently, with no temporal structure.
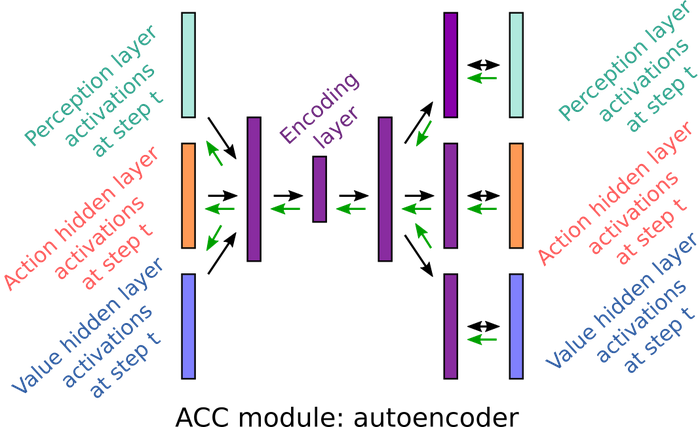
One-step predictor: same structure, but trained to predict activations at t+1 from t. Captures immediate transitions but assumes a Markov structure, missing longer-range patterns.
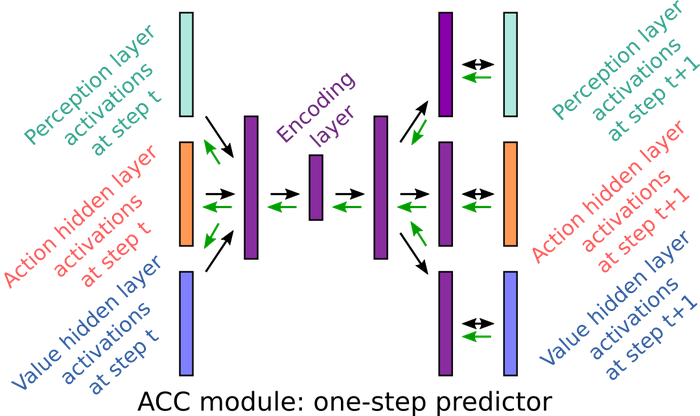
Recurrent predictor (LSTM): adds recurrent connections to capture extended temporal patterns. Better suited to represent behavioral sequences unfolding over many steps.
Recurrent predictor with predictive coding: the most complex module. Instead of receiving raw activations, it receives only the prediction error — the difference between what it expected and what actually happened. This forces the module to maintain its own internal predictions over time rather than relying on moment-to-moment input, compelling it to encode longer-range temporal structure. A secondary approach (information bottleneck) achieves a similar effect by penalizing information flow into the module rather than subtracting predictions; both encourage the module to internalize rather than react.
All four modules achieve satisfying predictive accuracy, with mean error around 0.1 on activations normalized to the [−1, 1] range.
What the representations look like
Visualizing individual unit activations in the LSTM module across a full episode reveals that the module is doing something meaningful: representations track game events and shift at level transitions, and similar stages across different levels produce similar activation patterns.
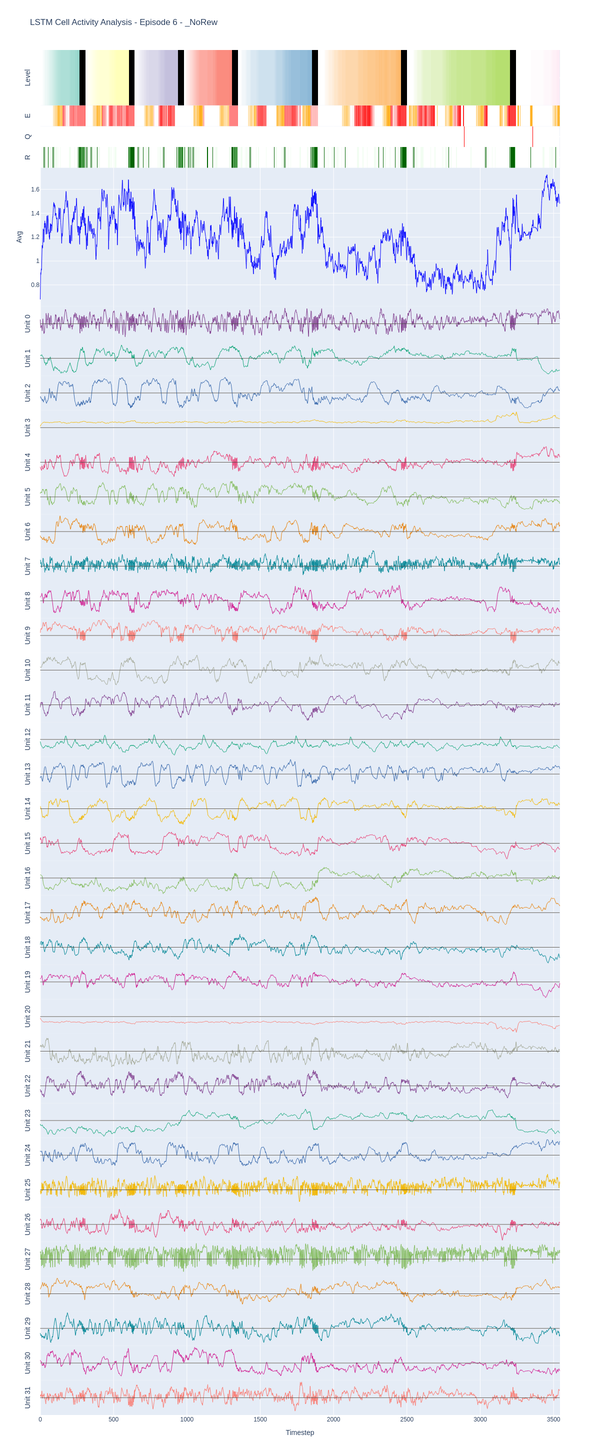
Individual unit activations in the LSTM ACC module across one episode, with game events (level transitions, enemy encounters, deaths) overlaid. Representations shift systematically at key moments.
Representational dissimilarity matrices (RDMs) make this quantitative. An RDM compares the internal representations at every pair of time steps: cells close to zero mean the representations were similar, cells close to one mean they were different. The matrix below encodes a simple reference: same level or different level.

A reference RDM encoding level identity (0 = same level, 1 = different level). The diagonal blocks correspond to time steps within the same level.
The RDM for the predictive coding ACC module shows a richer structure:
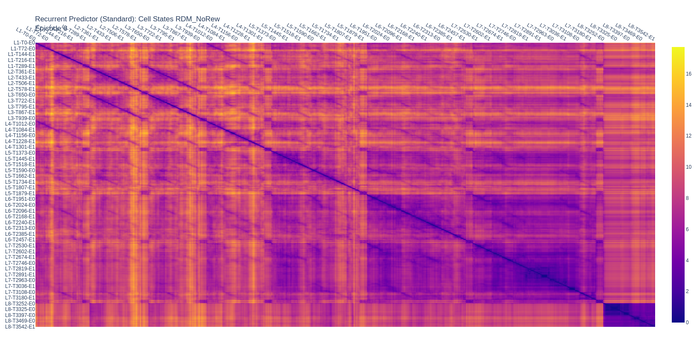
RDM for the predictive coding ACC module. Dark streaks extending off the main diagonal indicate that the module assigns similar internal representations to equivalent stages across different levels — some levels (including levels 2 and 3) are particularly close in representational space. Level 8 stands out as markedly different from all others, consistent with the agent failing to generalize its policy there. The module is not just tracking which level it is in: it is capturing something about the structure and progression of behavior that repeats across the game.
Controller module (unfinished)
A fifth module attempted to go beyond observation and actively intervene in the agent’s behavior, modeling not just the ACC but a rudimentary prefrontal control system. The core idea: use a variational autoencoder to generate candidate action sequences, evaluate them with the critic, and override the base model when the controller predicted a better long-term outcome.
This did not work reliably. The architecture is unstable during learning, and the design decisions made under time pressure at the end of the project were not careful enough. It remains interesting in principle: the same representational machinery that makes the predictive coding module a good observer could give a controller privileged access to the agent’s behavioral state. Getting it right will take more time.
Status
On hold. The observer modules work well and the representational analyses are informative; results were presented at the 2025 RLDM conference (poster). Whether and when to return to the controller problem is an open question.
This work was carried out during my postdoc in Clay Holroyd’s Learning and Cognitive Control Lab at Ghent University, funded by the European Research Council under the EU’s Horizon 2020 programme (grant 787307).